BenchMARL
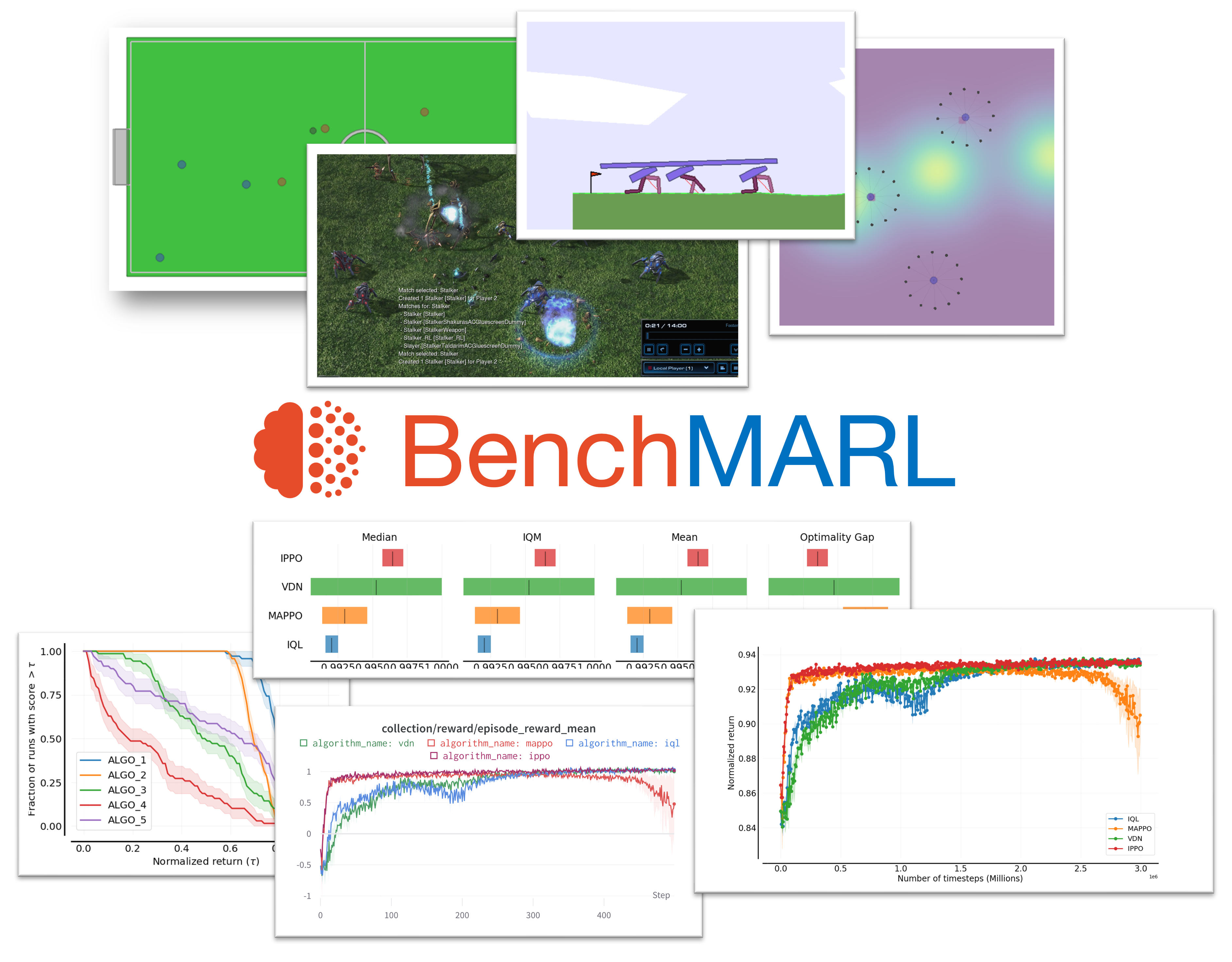
BenchMARL is a Multi-Agent Reinforcement Learning (MARL) training library created to enable reproducibility and benchmarking across different MARL algorithms and environments. Its mission is to present a standardized interface that allows easy integration of new algorithms and environments to provide a fair comparison with existing solutions. BenchMARL uses TorchRL and PyTorch as its backend, which grants it high performance and state-of-the-art implementations. It also uses hydra for flexible and modular configuration, and its data reporting is compatible with marl-eval for standardised and statistically strong evaluations.
BenchMARL core design tenets are:
Reproducibility through systematical grounding and standardization of configuration
Standardised and statistically-strong plotting and reporting
Experiments that are independent of the algorithm, environment, and model choices
Breadth over the MARL ecosystem
Easy implementation of new algorithms, environments, and models
Leveraging the know-how and infrastructure of TorchRL without reinventing the wheel
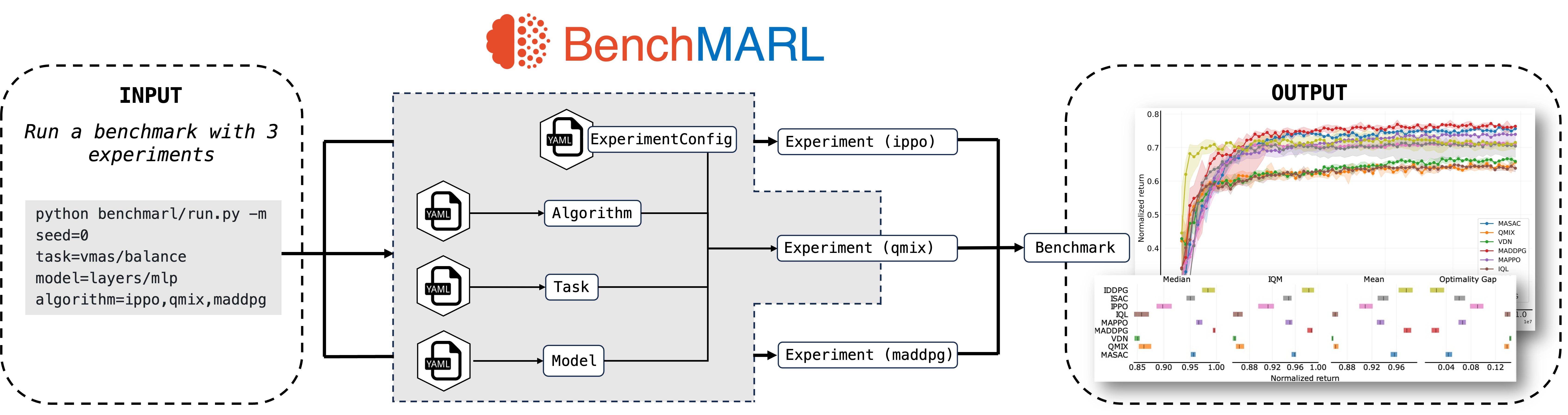
BenchMARL execution diagram. Users run benchmarks as sets of experiments, where each experiment loads its components from the respective YAML configuration files.
Why would I BenchMARL 🤔?
Why would you BenchMARL, I see you ask. Well, you can BenchMARL to compare different algorithms, environments, models, to check how your new research compares to existing ones, or if you just want to approach the domain and want to easily take a picture of the landscape.
Usage
Package Reference